Home
"Streamlined pipeline and database development: leveraging open-source platforms for automated data integration and cloud storage."
1. Datasets
This project aims to aggregate public meteorological, hydrogeologic, geospatial, and oceanographic data into a comprehensive dataset for machine learning-based watertable elevation modeling in Miami, Florida. As climate change impacts sea levels and storm intensity, understanding groundwater levels becomes essential for flood planning in low-lying regions. The dataset will automatically update with new data through a custom pipeline on the Dagster platform, streamlining data integration and reducing manual effort.
Meteorological data, including daily metrics like temperature, humidity, and wind speed, were collected from two sources. The Visual Crossing Weather API [1] provided comprehensive historical data, while extreme weather events since 1950 were sourced from NOAA's National Centers for Environmental Information [2]. This selection prioritized data availability from the earliest records to the present.
Hydrogeological and geospatial data, specifically groundwater levels and location details, were obtained from the USGS Water Services [3] and Google Maps API [4]. This included coordinates, depth to groundwater, and elevation above sea level, with a focus on data availability from the earliest records to present.
Sea level data, comprising monthly and daily averages, were sourced from NOAA's Tides and Currents [5], specifically from the Virginia Key station in Biscayne Bay. Measurements are reported in meters above NOAA's established datum.
2. Variables
The variables in this project encompass both raw data extracted directly from sources and aggregated data processed through a Python script in the Dagster pipeline before being appended to BigQuery tables. These variables serve as the foundation for our data engineering efforts, not yet modeled features but crucial building blocks for analysis:
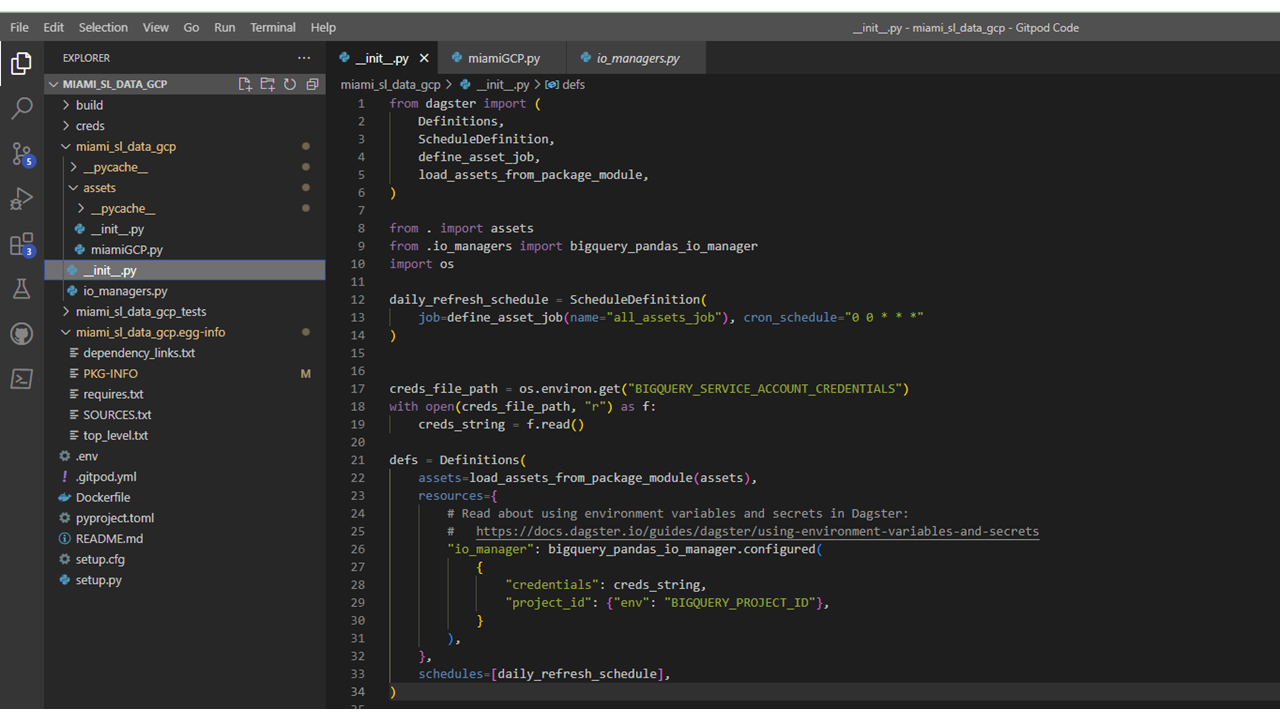
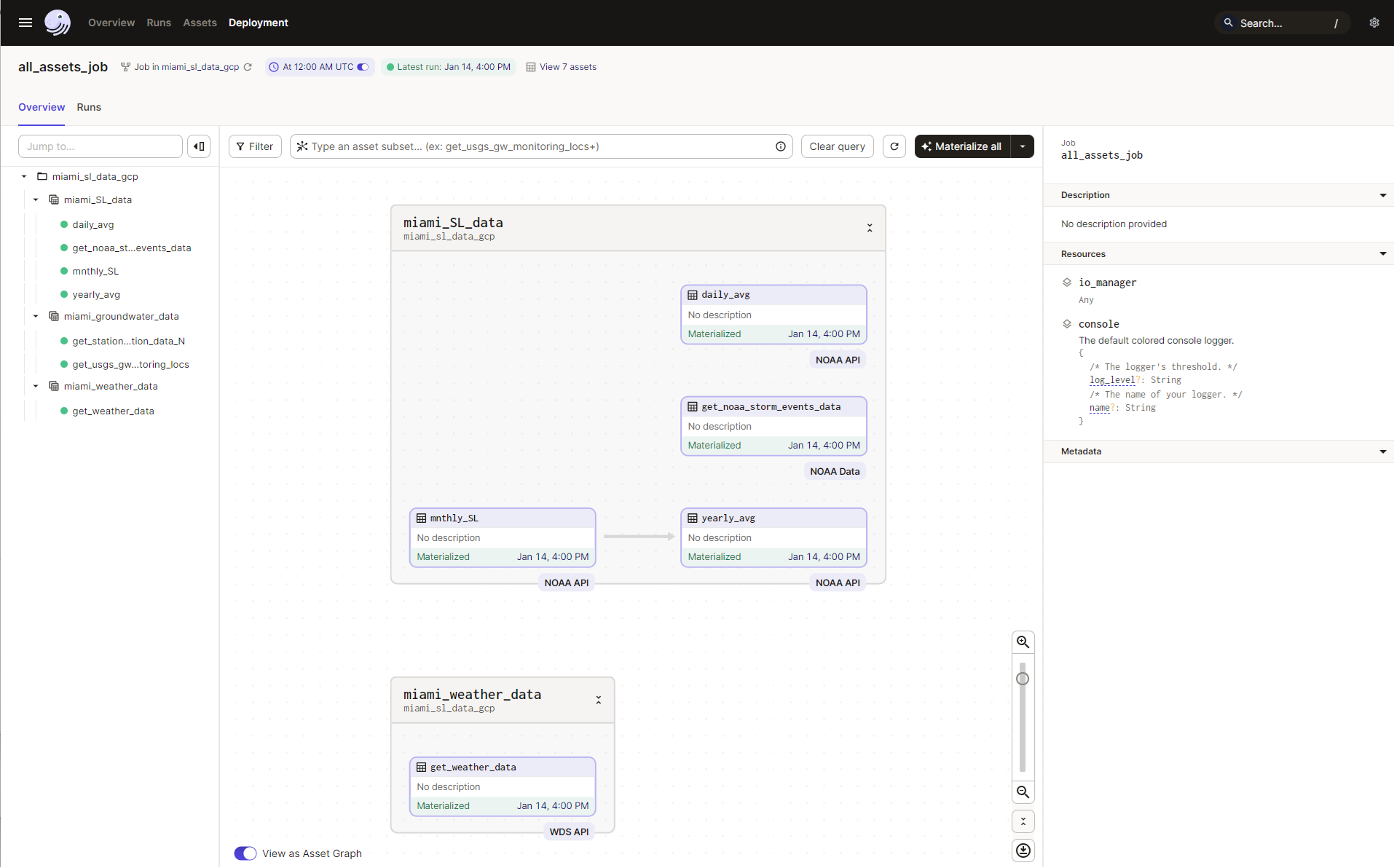
These datasets were extracted from their sources and directly imported into Google BigQuery tables through a pipeline created using a Dagster input/output manager (Figure 1). Running the pipeline from an integrated development environment (IDE) creates and instance of of the Dagster platform which can then be opened in a browser (Figure 2). From the platform GUI, users can perform many functions for orchestrating complex pipelines and data workflows. For example, schedulers can be created to automatically run the pipline at desginated time intervals (e.g. daily at midnight).
3. Data Model Implementation
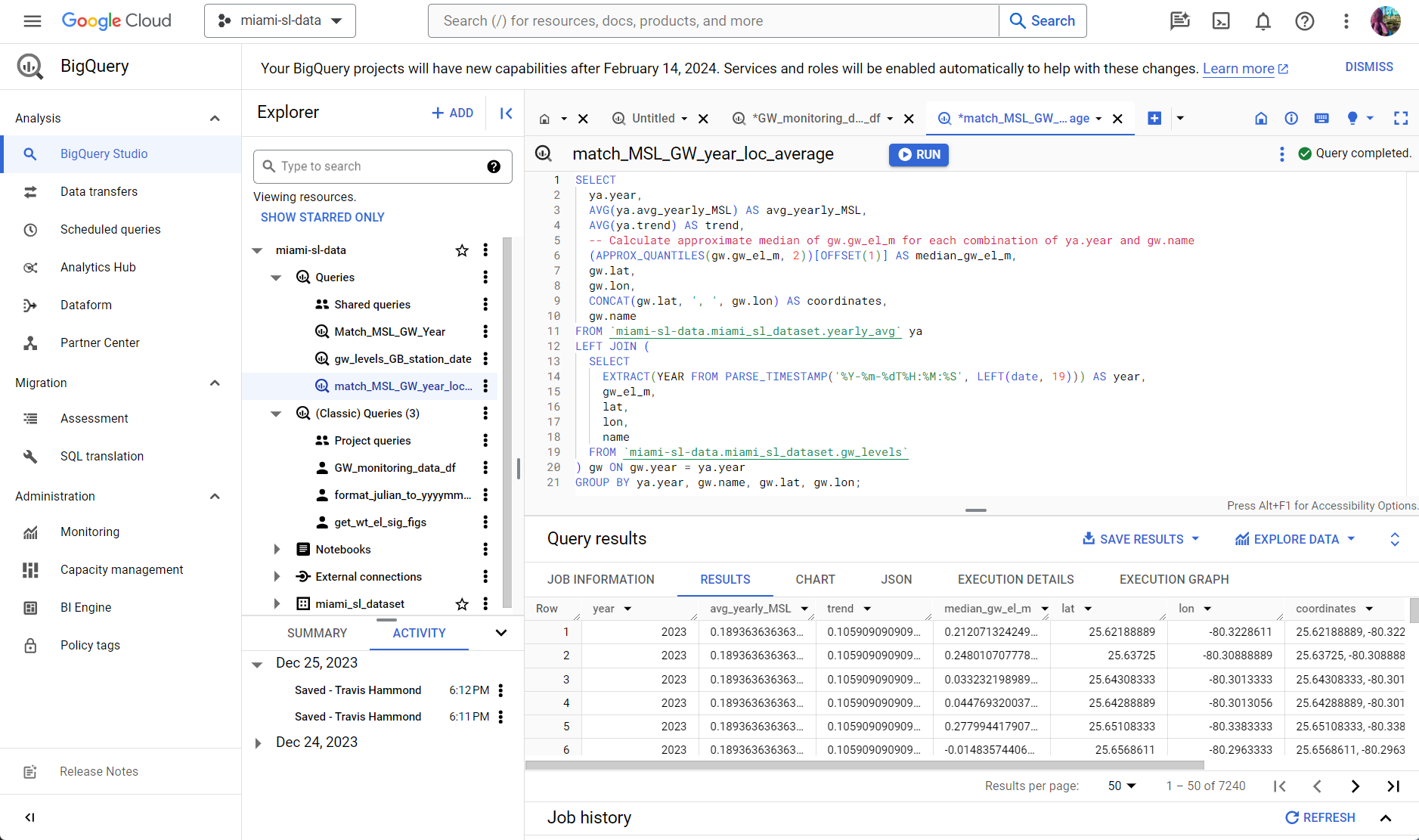
Implementing the data model is straightforward in our approach. The execution of the Dagster pipeline, illustrated in Figures 1 and 2, periodically updates assets within Google BigQuery. These assets, including data tables, are readily queried for diverse project needs (Figure 3). The data lake, operating on an SQL platform, allows for the saving of new queries as separate tables. While parallelization is an option for handling larger datasets, it was not required for this project's scale.
From this data lake, datasets for machine learning modeling are prepared and exported. Configuration steps such as exploratory data analysis (EDA), data cleaning, missing data handling, and feature engineering are all conducted within the Google Cloud Platform (GCP), linking BigQuery to other GCP tools like Looker Studio, Google Sheets, and CoLab notebooks for comprehensive data manipulation and analysis.
4. Data Lake Analytics
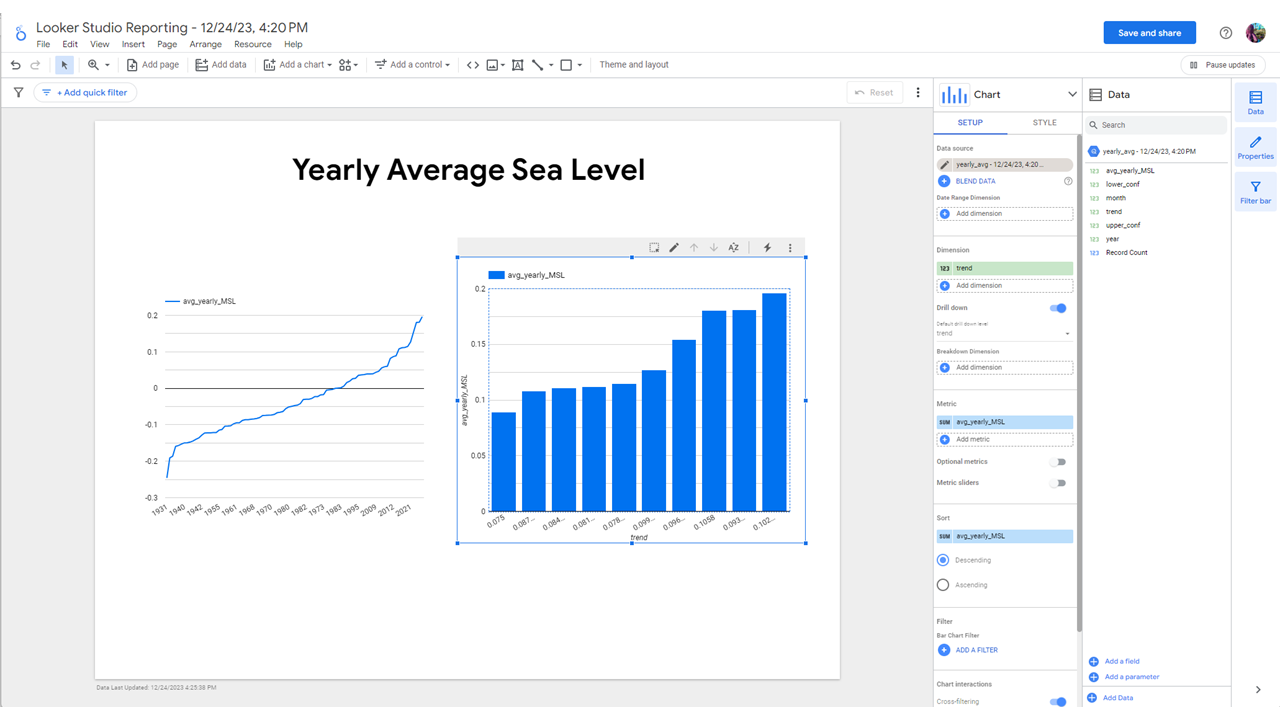
Analytics is conducted within GCP using Looker Studio, enabling us to assess the impact of sea level, among other factors, on local aquifer elevations. Trend plots, derived directly from BigQuery tables, illustrate this relationship clearly (Figure 4).
Additionally, we utilize Looker Studio for geospatial analysis, representing median water table elevation at various locations on a bubble plot map. This visual tool allows for an in-depth examination by adding dimensions such as median water table elevation per location against specific yearly sea levels, showcasing the flexibility of GCP's analytical tools (Figure 5).
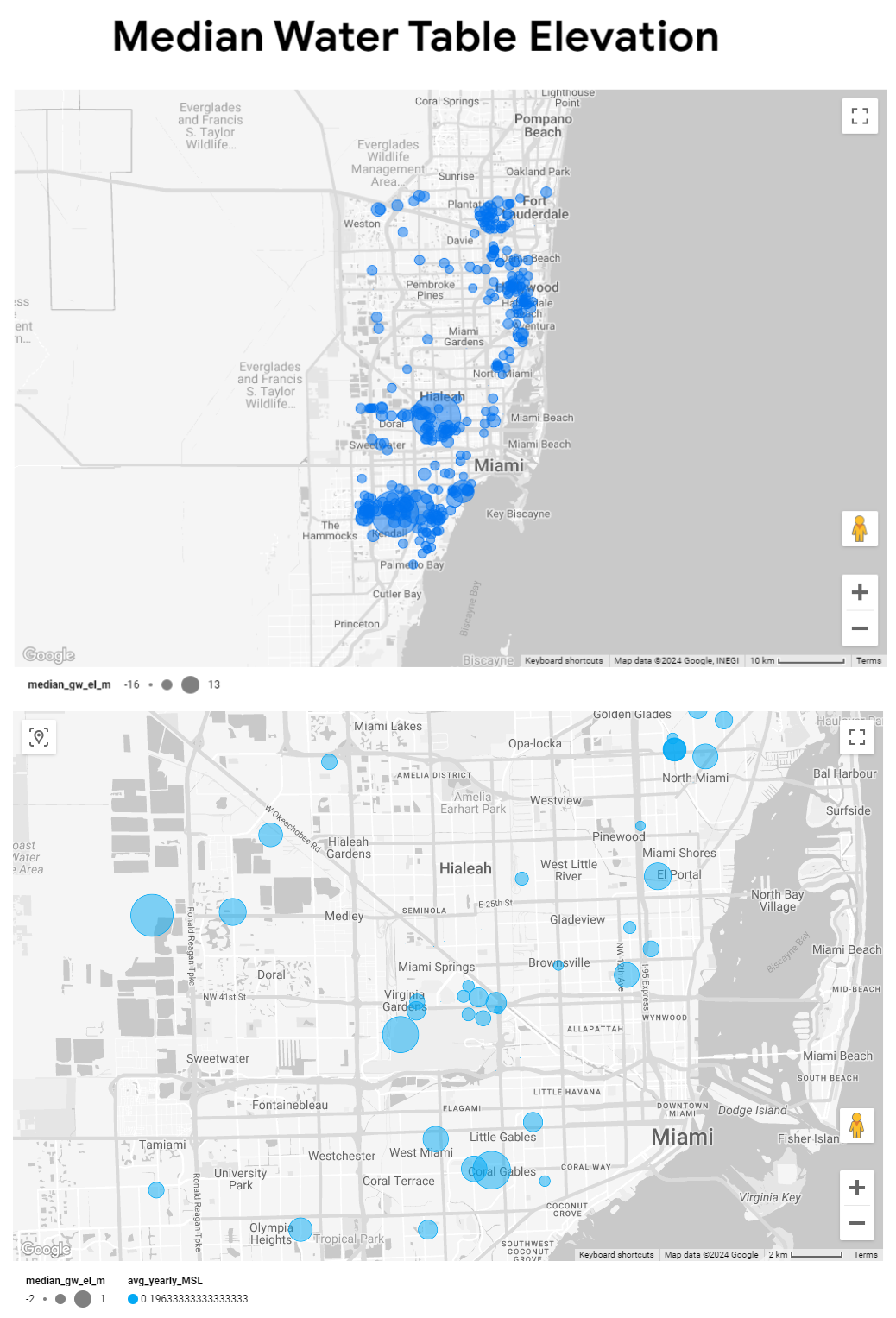
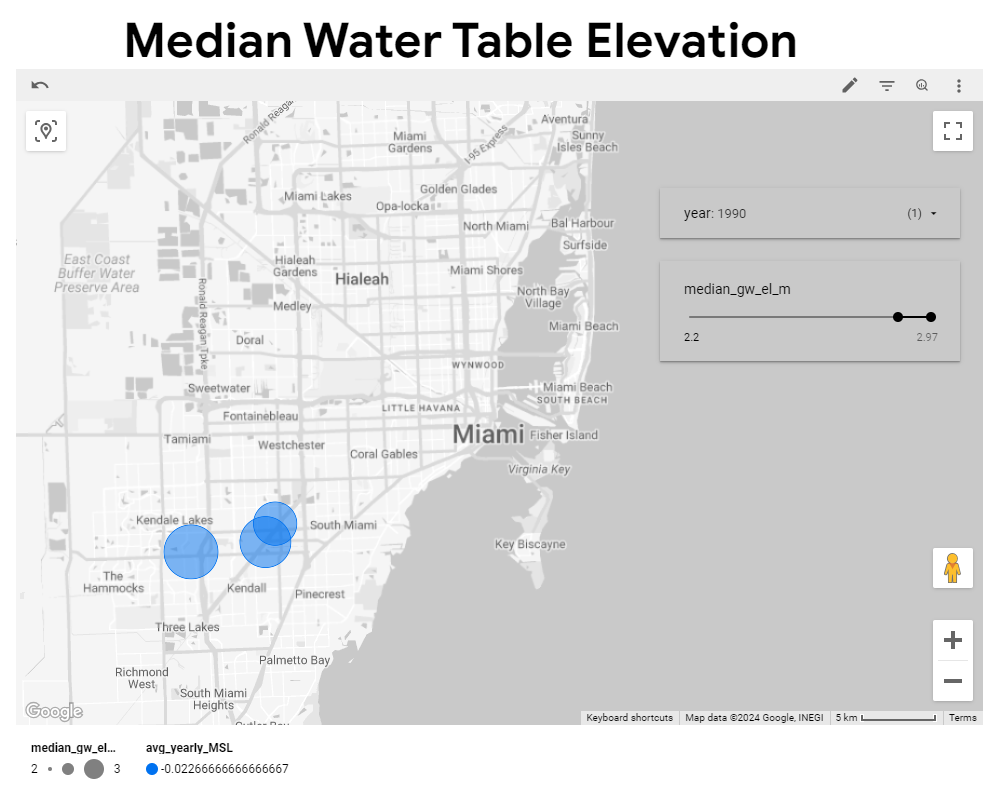
Chart controls, including dropdown lists and sliders, enhance data drill-down capabilities. These controls allow users to filter data by year for sea level elevation or by a range of median water table elevation values, facilitating a nuanced analysis of the interaction between sea levels and groundwater (Figure 6).
5. Conclusions
In conclusion, the development of a data lake for environmental data has proven to be a significant step forward in understanding and managing the impacts of climate change on local ecosystems, particularly in coastal areas like Miami, Florida. This project has successfully demonstrated how the integration of diverse datasets—ranging from meteorological and hydrogeological to geospatial and oceanographic—can provide a comprehensive view of environmental changes and their potential impacts.
The automation of data collection and integration processes through the use of cutting-edge technologies like Dagster and the storage and analysis capabilities of Google BigQuery have not only streamlined the workflow but also enabled the handling of large volumes of data with efficiency and scalability. The analytics performed within this data lake, including the visualization of sea level trends and groundwater levels, offer valuable insights that are crucial for effective environmental management and planning.
Looking ahead, the continued expansion and refinement of this data lake with real-time data feeds and more granular data will enhance its utility for predictive modeling and decision-making. The methodologies and findings of this project underscore the importance of leveraging technology and data science in the fight against climate change, offering a blueprint for similar initiatives globally. As we move forward, it will be imperative to engage with a broader spectrum of stakeholders, including governmental agencies, research institutions, and the community, to fully realize the potential of these technologies in environmental preservation and sustainable development.
6. References